When it comes to Large Language Models, understanding determinism is crucial for ensuring the reliability and consistency of their outputs. One common misconception is that temperature controls all aspects of an LLM, from floating-point arithmetic to GPU parallelism and batch composition. However, the truth is that temperature only affects the token sampling step in LLM models.
So, what exactly does temperature control? In simple terms, temperature regulates the randomness of a model’s output. Think of it as a thermostat that adjusts the level of “noise” in a model’s predictions. Lower temperatures result in more confident predictions, while higher temperatures allow for more diverse and creative output. But here’s the thing: temperature has no impact on the underlying math or architecture of an LLM.
Now, let’s talk about determinism. LLM determinism refers to the ability to produce byte-identical outputs under the same conditions. This means that if you run the same input through an LLM twice, the output should be identical, down to the last byte. Determinism is often confused with reliability, which is the ability of an LLM to produce consistent outputs in production environments.
While determinism is an essential property of any reliable LLM, it’s not the only factor at play. An LLM can be deterministic but still produce unreliable output if it’s not properly trained or deployed. Conversely, an LLM can be non-deterministic but still produce highly reliable output if it’s designed to handle variability.
Ultimately, achieving LLM determinism requires a deep understanding of the model’s architecture, training process, and deployment environment. By separating the concepts of determinism and reliability, we can develop more robust and predictable LLMs that deliver consistent and reliable performance.

LLM Model Consistency
When it comes to Large Language Models, consistency is a double-edged sword. On one hand, it’s a crucial factor in ensuring that your AI-powered applications deliver reliable and predictable results. On the other hand, hosted APIs can sometimes undermine this consistency, leading to unexpected outcomes.
Hosted APIs process prompts in dynamic batches with other users’ requests, leading to subtly different logits and outputs. This might seem like a minor issue, but it can have significant implications for your application’s performance and user experience. For instance, if your model is trained to produce identical outputs for identical inputs, but the hosted API introduces variability due to batch processing, your application may start producing inconsistent results.
Another factor that affects consistency is model size. While larger models are often touted for their ability to capture subtle nuances in language, they can also introduce variability in their outputs. In fact, model size can affect consistency, with larger models producing identical outputs in fewer instances. This is because larger models have more parameters to learn, which can lead to differences in their behavior, even when given the same input.
Even “pinned” model versions, which are intended to maintain a consistent behavior over time, can silently drift and change behavior. This is a major concern for applications that rely heavily on LLM determinism, where the output is directly tied to the input. In such cases, any deviation from the expected behavior can have significant consequences.
As a result, it’s essential to carefully evaluate the consistency of your LLM model, especially when working with hosted APIs. By understanding the factors that affect consistency, you can take proactive steps to mitigate variability and ensure that your application delivers reliable and predictable results.
Production Risks
The real production danger is silent degradation, where a classifier or parser works reliably one month but fails the next. It’s a ticking time bomb of unpredictability, waiting to unleash its fury on unsuspecting users. But why does this happen? The answer lies in the way we approach testing and validation.
When dealing with Large Language Model outputs, engineers often rely on string equality to verify the results. They compare the output to a predefined string, expecting a perfect match. But this approach is flawed. It assumes that the model will always produce the same output for a given input, which is not the case.
In reality, LLM determinism is often misunderstood in production environments. The model’s behavior is influenced by a complex interplay of factors, including the input data, the model’s architecture, and the training process. As a result, even a small change in one of these factors can cause the model’s output to shift, leading to silent degradation.
To mitigate this risk, engineers should test for behavioral consistency, not string equality. This means evaluating the model’s output in terms of its intended behavior, rather than just checking for a specific string. For example, if the model is intended to classify text as either positive or negative, the test should verify that the output is consistently correct, rather than just checking for a specific string.
By adopting this approach, engineers can ensure that their LLM-based systems are more robust and reliable, and better equipped to handle the complex and unpredictable nature of real-world data.

Reliability and Testing
When it comes to Large Language Models, reliability and testing are crucial to ensure that the models behave consistently and produce high-quality output. However, as LLMs are highly complex systems, it’s not always easy to predict how they’ll behave in different scenarios.
Structured outputs with schema validation can catch format drift and detect changes in LLM behavior. This means that even if an LLM is designed to produce a specific output format, schema validation can identify any deviations and alert developers to potential issues.
But schema validation is just one part of the equation. To truly ensure the reliability of an LLM, developers should run prompt regression tests before every model version change. This involves testing the LLM’s response to a wide range of prompts to ensure that it behaves consistently and produces the expected output.
LLM observability tools can also play a critical role in ensuring the reliability of an LLM. By scoring live production traces, these tools can detect quality drift between releases and alert developers to potential issues. This means that even if an LLM is performing well initially, it can still undergo changes in behavior that affect its overall reliability.
In fact, research has shown that LLM determinism, a key concept in understanding LLM behavior, is critical to ensuring the reliability of these models. LLM determinism refers to the ability of an LLM to produce consistent output given a fixed set of inputs. When an LLM is deterministic, it’s easier to predict how it will behave in different scenarios, which makes it easier to ensure that the model is reliable and produces high-quality output.
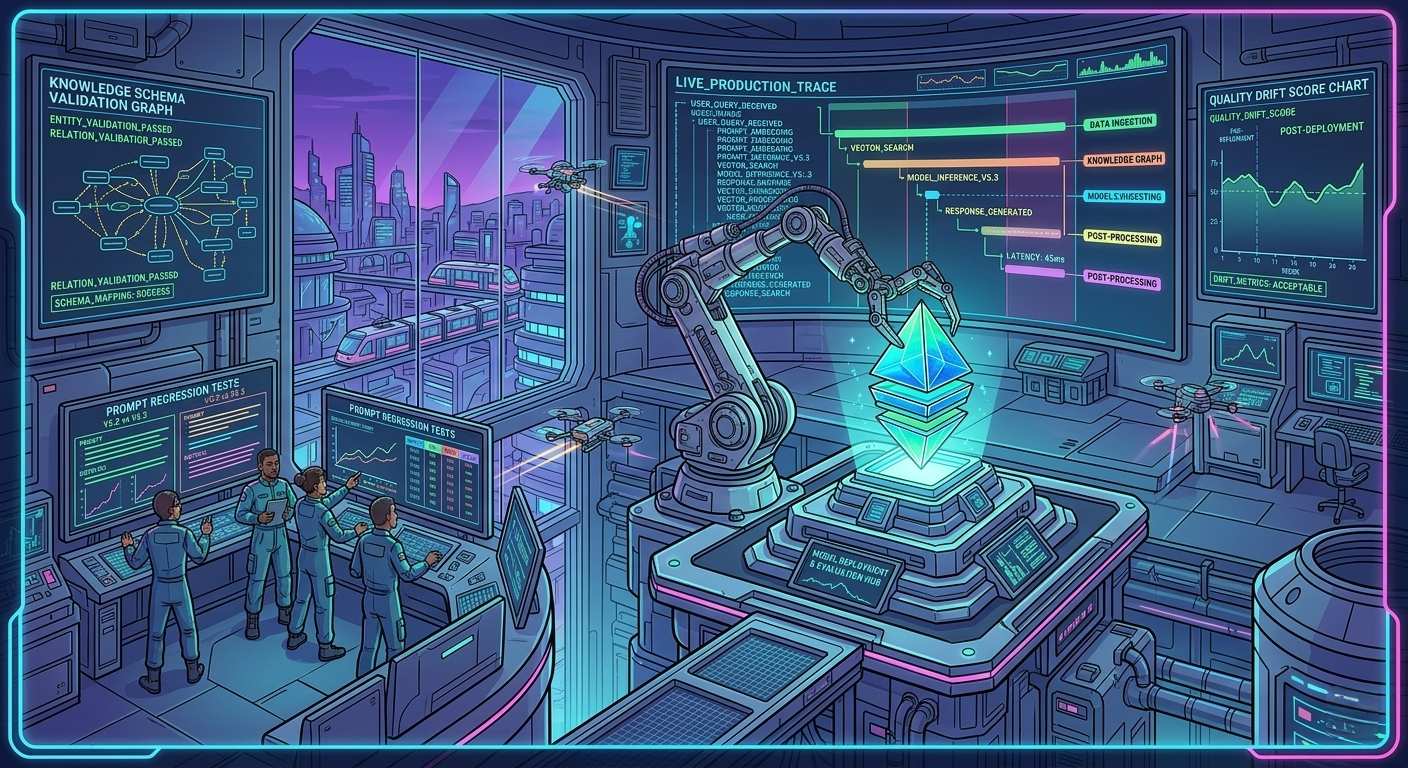
Best Practices
When working with Large Language Models, it’s essential to follow best practices that balance reproducibility with the complexity of the underlying technology. One crucial aspect is the use of seed parameters.
Exposing a seed parameter can significantly aid in reproducibility, as it allows for the recreation of specific model outputs under the same conditions. However, this approach comes with a catch – the seed parameter may break when backend infrastructure changes. This can be particularly problematic in large-scale deployments where infrastructure updates are a regular occurrence.
Anthropic, a leading AI organization, has taken a different approach. Their LLMs do not expose a stable seed parameter, making reproducibility more challenging. While this may not be a significant issue in certain use cases, it highlights the trade-offs involved in balancing reproducibility with the need for flexibility in a rapidly evolving AI landscape.
So, what can engineers do to ensure reliable testing of LLM outputs? The answer lies in focusing on behavioral consistency. This involves testing the LLM’s responses to a wide range of inputs and scenarios, rather than relying solely on specific seed values. By doing so, engineers can gain a deeper understanding of the LLM’s behavior and limitations, ultimately leading to more robust and reliable AI systems.
In the pursuit of LLM determinism, where outputs are predictable and consistent, engineers must navigate these complexities carefully. By prioritizing behavioral consistency and adopting a flexible approach to testing, they can create AI systems that are both reliable and effective.

Determinism Is Hard To Get
As we’ve explored the world of LLMs, it’s become increasingly clear that deterministic outputs are the holy grail of reliable AI systems. But, what does it mean to achieve LLM determinism? In short, it’s the ability of a model to produce consistent outputs given the same input, every time. Sounds straightforward, right? Not quite. LLM determinism is not the same as reliability, and engineers should focus on producing consistent outputs.
Think about it like a software release. You can have a reliable model that works perfectly 99.9% of the time, but still produce wildly different outputs for the same input. This is where silent degradation comes in – a significant production risk that can be disastrous for users and the business. Silent degradation refers to the scenario where a model starts producing inconsistent outputs without warning, often due to changes in the data, model drift, or other underlying factors.
So, how do we ensure our LLMs are reliable and produce consistent outputs? A practical reliability stack includes several key components. First, structured outputs provide a clear and consistent format for model responses, making it easier to detect any deviations. Second, prompt regression tests allow us to verify that our models are working as expected, even in the face of changing inputs or data. Finally, LLM observability tools give us visibility into the inner workings of our models, enabling us to identify and address any issues before they become major problems. By focusing on LLM determinism and building a robust reliability stack, we can create AI systems that are not only reliable but also trustworthy and effective.
