AI engineering is shifting from pure model building to system design, where integrating models into reliable backend services is the main challenge. Modern AI stacks combine Large Language Models, data pipelines, and observability, making them closer to distributed systems than traditional ML workflows. Gone are the days when you were asked about just general software engineering principles. Now it is very common to be asked about the latest libraries for AI engineering. It is a very dynamic field. And while it is impossible to stay up to date with all of the libraries, there are definitely a few most popular ones that should be followed. Today, we will go through the main AI engineering libraries and see what is the current status of the most frequently used ones.
When it comes to AI engineering libraries, the landscape is constantly evolving. However, there are a few key players that have managed to establish themselves as industry leaders. TensorFlow, for instance, has been a stalwart in the AI engineering space for years. Its flexibility and customizability make it a favorite among developers. However, it’s worth noting that TensorFlow can be a bit of a beast to manage, especially for smaller projects.
Another AI engineering library that has gained significant traction is PyTorch. Known for its ease of use and rapid development capabilities, PyTorch has become a go-to choice for many developers. Its dynamic computation graph and automatic differentiation make it an ideal choice for building and testing AI models.
In recent years, we’ve also seen the rise of other AI engineering libraries and models that are provided to public, like Hugging Face. This platform has made it incredibly easy to integrate pre-trained models into a wide range of applications. Its community-driven approach has also made it a favorite among developers.
Lastly, we can’t forget about the importance of integrating these AI engineering libraries into a robust system design. This means not just focusing on the model itself, but also on the surrounding infrastructure and tools that support it.

AI Engineering Orchestration
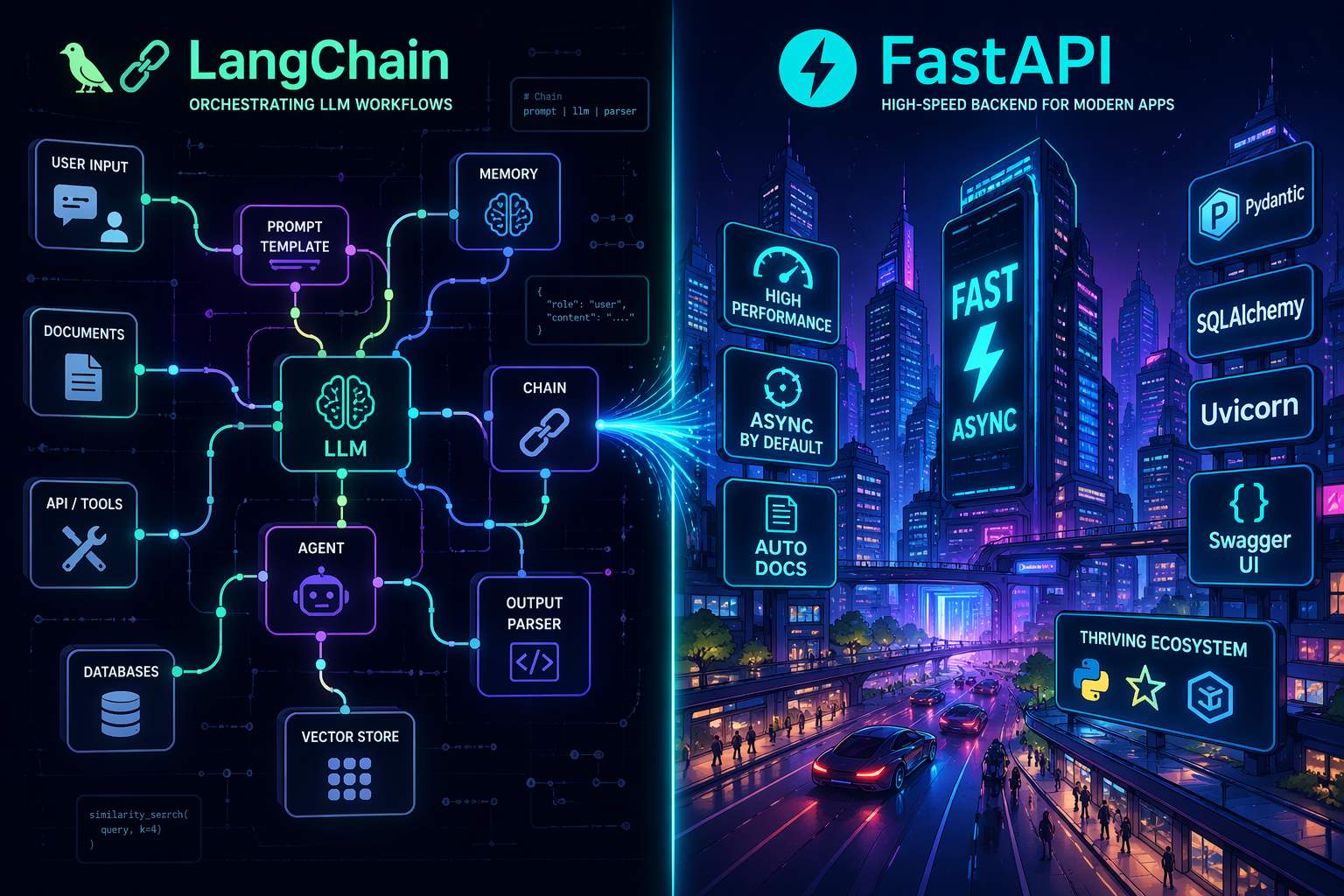
LangChain is widely used for orchestrating LLM workflows (prompting, chaining, tools, memory), but is often criticized for abstraction overhead in production systems.
AI engineering libraries like FastAPI remain the dominant backend frameworks for serving AI models due to speed, async support, and ecosystem compatibility. But what really sets them apart is their ability to seamlessly integrate with the latest innovations in the field. By leveraging the power of AI engineering libraries, developers can create scalable and efficient models that meet the demands of modern applications.
One of the key benefits of these libraries is their ability to handle complex tasks with ease. Whether it’s handling multiple requests at once or managing memory-intensive tasks, they provide a robust foundation for building high-performance applications. This is particularly important when it comes to serving AI models, where even slight delays can have a significant impact on user experience.
FastAPI, in particular, has gained widespread adoption due to its unique blend of speed, async support, and ecosystem compatibility. By using this library, developers can create applications that are not only fast and efficient but also easy to maintain and scale. This is essential for meeting the evolving needs of modern applications and ensuring that AI models continue to deliver value to end-users.
As the field of AI continues to evolve, it’s clear that AI engineering libraries will play an increasingly important role in shaping the future of application development. By providing a robust and scalable foundation for building high-performance applications, they’re empowering developers to push the boundaries of what’s possible with AI.
Distributed Workloads and Observability
When it comes to building and deploying AI applications, two crucial areas often get overlooked: distributed workloads and observability. These components are vital to ensuring the smooth operation of your AI systems and preventing those frustrating moments of downtime and lost productivity.
Distributed workloads refer to the ability of your system to handle multiple tasks simultaneously, without slowing down or crashing. This is where Ray and Celery come into play. These two powerful libraries are designed specifically for distributed workloads and background processing, making them an ideal choice for tasks like batch inference and pipeline orchestration. By leveraging these tools, you can break down complex tasks into manageable pieces and execute them in parallel, resulting in faster processing times and improved overall performance.
However, even with the best distributed workloads in place, issues can still arise. This is where observability tools come in – critical components that provide you with the insights you need to debug and optimize your AI system. LangSmith and Langfuse are two such tools that shine in this regard. By providing detailed information on LLM behavior, prompt tracking, latency, cost, and failures in production, these tools empower you to identify and address issues quickly, ensuring that your AI system runs smoothly and efficiently.
In the world of AI engineering, leveraging the right libraries is key to success. By combining the strengths of AI engineering libraries with distributed workloads and observability tools, you can unlock the full potential of your AI applications and take your project to the next level. With Ray, Celery, LangSmith, and Langfuse at your disposal, you’ll be well-equipped to handle even the most complex AI engineering challenges that come your way.

RAG and Data Indexing
LlamaIndex is rising as a simpler alternative focused on RAG and data indexing for LLMs. The trend is moving toward simpler, composable architectures (direct API + lightweight orchestration) rather than heavy frameworks. This shift is driven by the need for faster development, improved efficiency, and more adaptability in the ever-evolving landscape of large language models.
RAG, or Retrieval-Augmented Generation, is a technique that has gained significant traction in the field of LLMs. It involves combining the strengths of traditional language models with the power of data retrieval to produce more accurate and informative responses. By leveraging RAG, developers can build more sophisticated models that are better equipped to handle complex queries and provide actionable insights.
As AI engineering libraries continue to mature, the integration of RAG and data indexing is becoming increasingly important. By combining these technologies, developers can unlock the full potential of LLMs and create more efficient, scalable, and adaptable models. This, in turn, enables the rapid development of innovative applications that can be deployed across various industries and domains.
The benefits of this approach are numerous. For instance, developers can now focus on building high-level applications without worrying about the underlying complexities of model development. Moreover, the use of direct APIs and lightweight orchestration enables faster iteration and more agile development, which is crucial in today’s fast-paced and competitive AI landscape.
As the field of LLMs continues to evolve, the importance of RAG and data indexing will only continue to grow. LlamaIndex, with its focus on simplicity and composability, is well-positioned to play a leading role in this trend. By embracing this approach, developers can unlock new possibilities for AI-powered applications and drive innovation in a wide range of industries.

SDKs From The Biggest Comeptitors
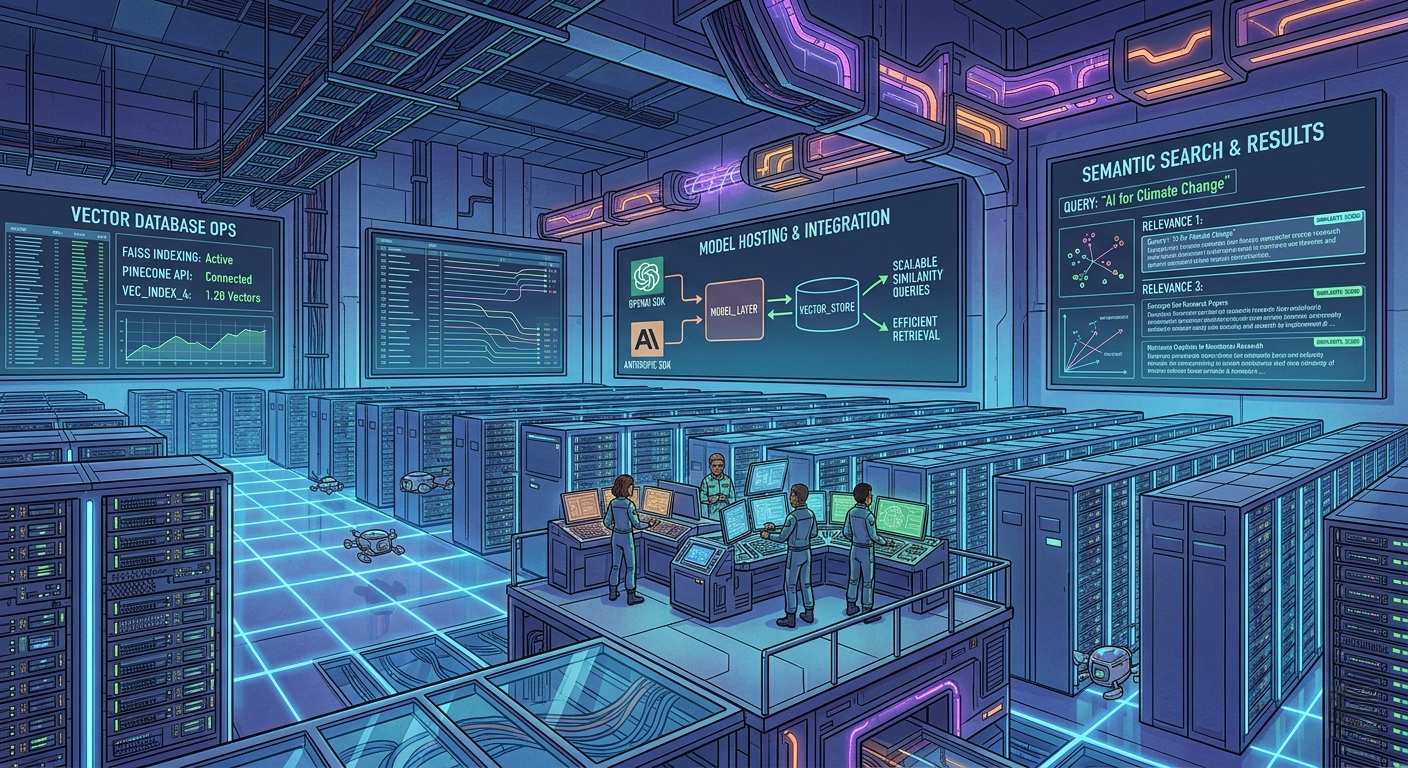
OpenAI / Anthropic SDKs are heavily used in production for inference, reducing the need for in-house model hosting. Vector databases (e.g., FAISS, Pinecone, Weaviate) are now core infrastructure for semantic search and RAG (retrieval-augmented generation), enabling scalable similarity queries over embeddings.
The AI landscape is rapidly evolving, and with it, the tools and infrastructure required to support the development and deployment of AI models. One significant trend is the adoption of OpenAI and Anthropic SDKs in production environments. These SDKs provide a scalable and efficient way to perform inference on AI models, reducing the need for in-house model hosting and management.
By leveraging these SDKs, developers can focus on building and integrating AI models into their applications, rather than worrying about the infrastructure required to support them. This shift has significant implications for the field of AI engineering, enabling developers to build more complex and sophisticated AI-powered systems.
Another key trend is the increasing importance of vector databases in the AI ecosystem. Vector databases such as FAISS, Pinecone, and Weaviate are now core infrastructure for semantic search and RAG (retrieval-augmented generation). These databases enable scalable similarity queries over embeddings, allowing developers to build more effective and efficient AI-powered systems.
The integration of AI engineering libraries, such as those provided by OpenAI and Anthropic, with vector databases is a powerful combination. By leveraging these libraries and databases, developers can build more sophisticated AI-powered systems, with improved performance, scalability, and efficiency. This trend is set to continue, with major implications for the field of AI engineering and the development of AI-powered systems. As the demand for AI-powered systems continues to grow, the importance of these infrastructure components will only continue to increase.
Dynamic Field That Keeps Changing
As we’ve explored the world of AI engineering, one thing has become increasingly clear: the trend is shifting toward simpler, composable architectures rather than heavy frameworks. This movement is driven by the need for greater flexibility and scalability in production systems, where AI models are being integrated at an unprecedented pace.
At the heart of this shift are AI engineering libraries – the unsung heroes of modern AI development. These libraries are the key to seamless integration of AI models into production systems, allowing developers to focus on higher-level tasks rather than getting bogged down in low-level implementation details.
However, the choice of AI engineering library can make all the difference. LangChain, for example, has been criticized for its abstraction overhead in production systems. While it offers a high-level interface for building AI applications, it can add complexity and overhead to the system as a whole. This can be a major challenge for teams looking to deploy AI models in production.
But what about in-house development of a custom backend system? While this approach offers complete control and customization, it can also be a significant challenge. Building a custom backend system requires a deep understanding of AI engineering, software development, and deployment – a tall order for many teams. Furthermore, the development process can be time-consuming and resource-intensive, taking away from the time and resources needed to focus on AI model development.
Ultimately, the choice between LangChain, in-house development, or other AI engineering libraries will depend on the specific needs and goals of the project. By considering the trade-offs and challenges of each approach, developers can make informed decisions that drive the success of their AI applications.
