AI-ready backends require three capabilities: streaming response support, vector storage access, and async concurrency. These capabilities work together to create a robust and efficient backend that can handle the demands of large language models.
Streaming response support is a game-changer for LLMs. It enables incremental token delivery, allowing your application to respond quickly to user input. Imagine a chatbot that can respond to a user’s question before they even finish typing – that’s the power of streaming response support. By breaking down the response into smaller chunks, you can improve the user experience and reduce the computational load on your backend.
Vector storage access is another crucial capability for AI backend stack. It allows your application to store and retrieve embeddings, which are the numerical representations of words, phrases, or other pieces of text. Embeddings are used in a variety of applications, including natural language processing and recommendation systems. With vector storage access, you can build more accurate and efficient models that can handle large amounts of data.
Async concurrency is the third key capability of AI-ready backends. It enables your application to handle parallel LLM API calls without blocking, which means you can process multiple requests simultaneously. This improves the performance and scalability of your application, making it more suitable for large-scale deployments. By leveraging async concurrency, you can build a more responsive and efficient AI backend stack that can handle the demands of modern applications.
The AI Backend Stack Evolution
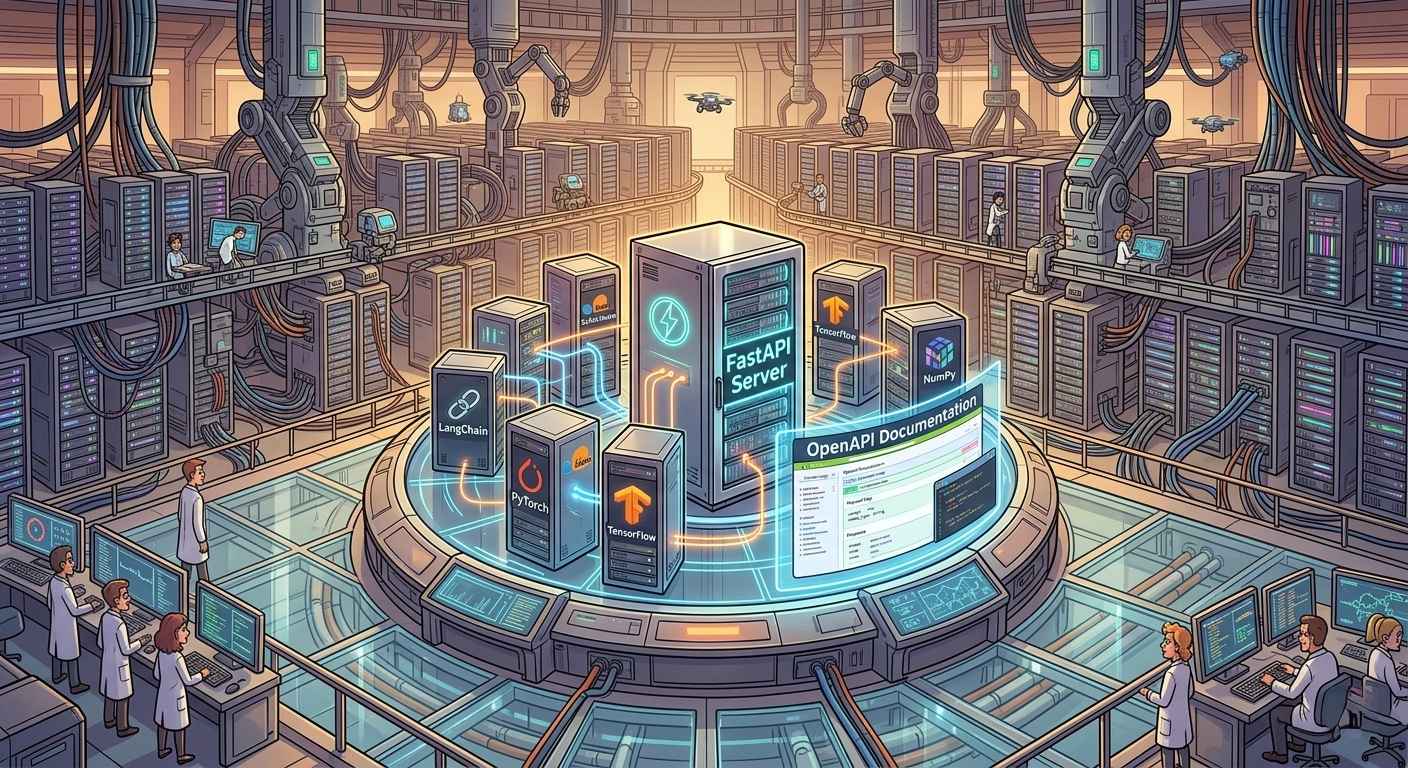
FastAPI is gaining popularity as the default entry point for AI backends due to its async API layer. This is largely due to the increasing demand for real-time AI model deployment. The async API layer allows for efficient handling of multiple requests, making it an ideal choice for scalable AI applications. As a result, FastAPI has become the go-to framework for developers looking to build a robust AI backend stack.
One of the key reasons FastAPI is gaining traction is its seamless integration with various machine learning libraries. It natively integrates with LangChain, PyTorch, and every major ML library, making it easy for developers to integrate AI models into their applications. This level of integration enables developers to focus on building AI-powered features, rather than worrying about the underlying infrastructure.
Another significant advantage of FastAPI is its ability to auto-generate OpenAPI docs. This feature keeps the frontend team in sync with the API without requiring extra effort from the development team. With auto-generated OpenAPI docs, developers can easily communicate the API’s functionality to the frontend team, reducing the likelihood of miscommunication and errors.
The rise of FastAPI has significant implications for the AI backend stack. As more developers adopt this framework, we can expect to see a shift towards more efficient and scalable AI deployment. The combination of FastAPI’s async API layer, seamless integration with ML libraries, and auto-generated OpenAPI docs make it an ideal choice for building robust AI backend stacks. As the demand for real-time AI model deployment continues to grow, FastAPI is poised to play a key role in shaping the future of the AI backend stack.
The Standardization of Tools
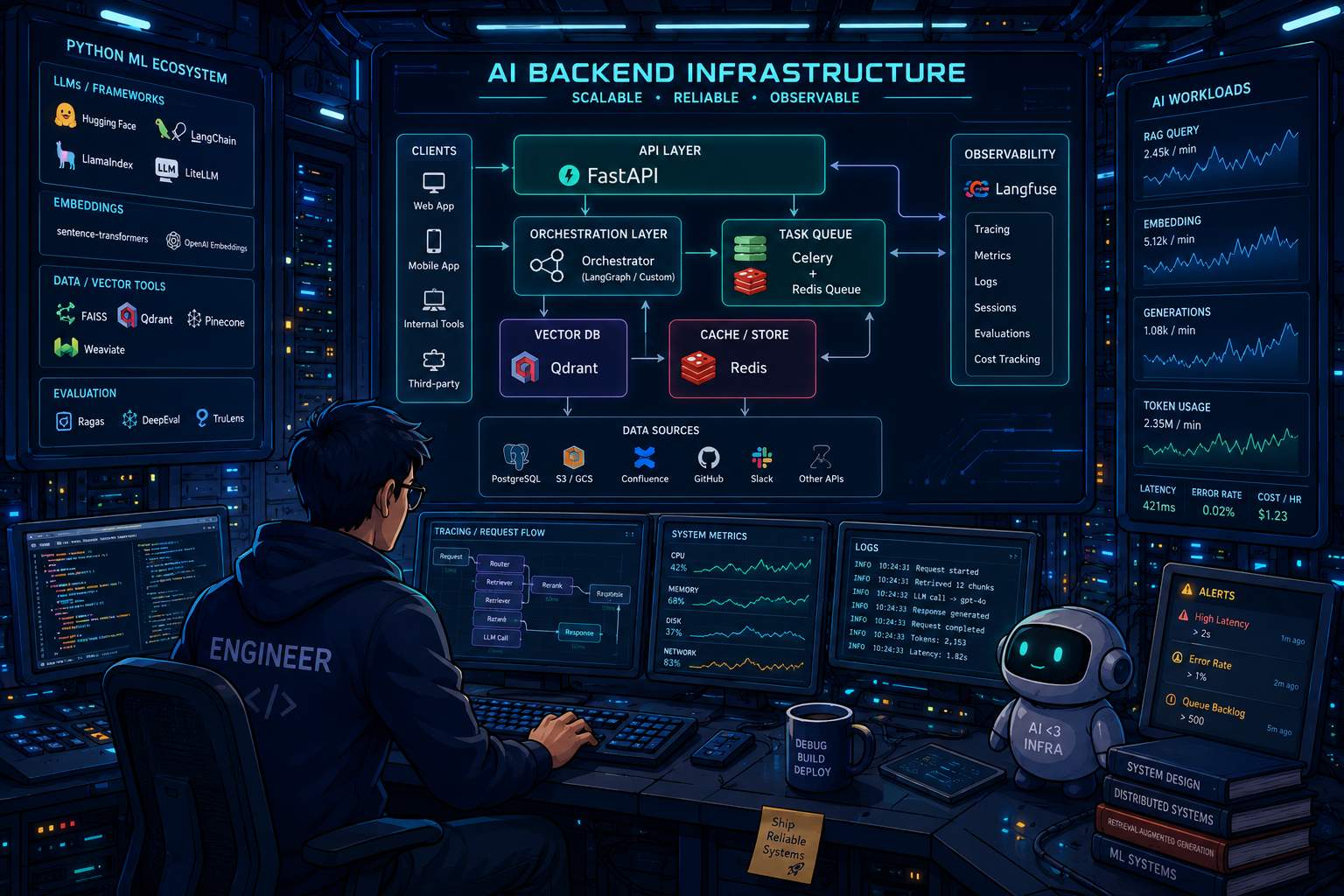
A new backend stack is standardizing around AI workloads, including FastAPI, a vector DB, Redis, a task queue, an orchestration layer, and an observability tool. This convergence of technologies is no surprise, given the rapid growth and adoption of AI in various industries. The resulting stack has become a go-to choice for many companies, especially those that require Python’s Machine Learning ecosystem to power their products.
Knowing this stack is quickly becoming a baseline career expectation for backend engineers, it’s essential to understand the components that make it tick. FastAPI, a modern Python web framework, provides a robust foundation for building scalable and high-performance APIs. Pair it with a vector DB, and you get a powerful tool for storing and querying large amounts of data. Redis, a popular in-memory data store, adds real-time capabilities to the mix, enabling fast and efficient data processing.
The inclusion of a task queue and an orchestration layer ensures seamless communication and coordination between microservices, making it easier to manage complex workflows. Lastly, an observability tool provides valuable insights into the system’s performance, helping developers identify bottlenecks and areas for improvement. This combination of technologies has become the backbone of many AI-powered products, from natural language processing to computer vision, and is widely used in industries such as healthcare, finance, and e-commerce.
As the demand for AI-powered solutions continues to grow, it’s likely that the AI backend stack will become even more standardized, with more companies adopting this technology stack to stay ahead of the curve. For backend engineers, staying up-to-date with the latest trends and technologies is crucial for career advancement and success in this rapidly evolving field.
The Importance of Context Engineering
In 2026, AI agents don’t struggle with reasoning, but with finding the right data at the right time. This paradigm shift in AI development has sparked a pressing need for a robust infrastructure that can efficiently store, index, and serve diverse types of data. Context engineering, a critical component of this infrastructure, has emerged as the most important problem in AI backend development today.
At its core, context engineering involves designing and implementing systems that can handle both structured and unstructured data, from short-term event logs to long-term knowledge bases. This requires a deep understanding of data types, formats, and retrieval patterns to ensure seamless integration with various AI models and applications.
A well-architected AI backend stack relies heavily on effective context engineering. It enables AI systems to learn from diverse data sources, adapt to changing environments, and make informed decisions in real-time. By providing a unified framework for data storage, indexing, and retrieval, context engineering empowers AI agents to access the right information at the right time, thereby improving their performance, accuracy, and overall decision-making capabilities.
The importance of context engineering cannot be overstated in today’s AI landscape. As AI agents become increasingly sophisticated, their ability to find relevant data in a timely manner will become a major differentiator between success and failure. By prioritizing context engineering and investing in cutting-edge technologies, organizations can build a robust AI backend stack that supports the development of intelligent, data-driven applications that can drive business growth and innovation.
The Rise of Task Queues
Task queues have become a crucial component in modern AI backend stacks, and for good reason. Large Language Models and image generation calls are notoriously slow and expensive to run inline in a request cycle. The costs associated with these operations can quickly add up, making it imperative for developers to find a more efficient solution.
That’s where task queues come in – a game-changing technology that enables asynchronous processing, ensuring that resource-intensive tasks like LLM and image generation calls are handled outside of the main request cycle. This approach not only improves performance but also reduces the financial burden on your AI backend stack.
But what exactly makes task queues so essential? For starters, they provide a robust and scalable way to handle tasks that might otherwise slow down or even crash your application. By offloading these tasks to a separate queue, you can ensure that your application remains responsive and efficient, even under heavy loads.
Async processing with retries and dead-letter queues is the minimum production standard for any serious AI backend stack. This approach ensures that tasks are retried when they fail, and that failed tasks are properly handled and logged, preventing errors from slipping through the cracks.
When it comes to implementing task queues, you have a range of options to choose from. Popular task queue options include Celery, Dramatiq, and raw SQS workers. Each has its own strengths and weaknesses, but they all share a common goal: to help you build a faster, more efficient, and more scalable AI backend stack that can handle the demands of modern applications.

The Orchestration and Observability Space
The AI orchestration space is rapidly evolving, with major players and new entrants vying for dominance. However, the trajectory suggests that this space is headed toward consolidation, with two or three framework winners emerging by 2026. But what does this mean for developers and businesses building their AI backend stack? In reality, it’s less about which framework will reign supreme and more about understanding the underlying primitives that make them tick.
Tool calling, memory management, and retrieval are just a few of the fundamental concepts that underpin the orchestration of AI systems. Rather than betting on a single framework, understanding these primitives will be key to unlocking efficient and scalable AI infrastructure. By grasping the intricacies of how these components interact, developers can build more robust and maintainable AI applications.
As the AI orchestration space continues to mature, observability tools are playing an increasingly critical role. Traditional observability tools like Sentry and New Relic have long been stalwarts in the industry, but a new wave of LLM-native tools is gaining traction. Langfuse and LangSmith are two notable examples, offering specialized observability capabilities tailored to the unique needs of large language models.
The rise of LLM-native tools is a reflection of the growing importance of AI in the enterprise. As more companies adopt AI-powered solutions, the need for specialized observability tools will only continue to grow. By staying ahead of the curve and investing in the right tools, businesses can ensure that their AI backend stack is optimized for performance, scalability, and reliability.
Conclusion
As we wrap up our exploration of the ever-changing AI landscape, it’s clear that the AI backend stack is evolving rapidly, with new tools and capabilities emerging every year. This acceleration is not slowing down, and backend engineers working on AI projects must be prepared to adapt and evolve alongside it.
To thrive in this environment, it’s essential to stay informed about the latest trends and technologies. By doing so, you’ll not only be able to tackle complex AI projects with confidence but also unlock new opportunities for innovation and growth. The good news is that there are plenty of resources available to help you stay up-to-date: from online courses and workshops to industry conferences and meetups.
One of the most significant benefits of staying current with the AI backend stack is the ability to make data-driven decisions. With a deep understanding of the latest tools and techniques, you’ll be able to analyze complex data sets, identify patterns, and make informed predictions. This, in turn, will enable you to create more accurate and effective AI models that drive real business value.
But staying ahead of the curve in the AI backend stack is not just about keeping up with the latest trends; it’s also about future-proofing your career. As AI continues to transform industries and revolutionize the way we live and work, the demand for skilled backend engineers will only continue to grow. By investing time and effort into staying current with the AI backend stack, you’ll not only be positioned for success today but also set yourself up for long-term career growth and opportunities.
