Modern LLM development has outgrown the era of quick scripts and prompt tinkering. Today, shipping a reliable AI-powered feature demands the same discipline as any backend service: clean dependency management, composable architecture, observable infrastructure, and a solid testing harness.
This post walks through the key engineering decisions made while building a production-ready LLM pipeline – a meeting summarizer – using Python, Groq, LangChain, and LangSmith. Whether you’re just starting to integrate LLMs into your stack or looking to harden an existing prototype, the patterns here translate directly to real-world systems.

The Modern Python Stack: Moving Beyond Pip
For this project, we bypassed traditional venv or poetry management in favor of uv. In a workspace containing multiple packages and python versions, uv provides superior primitives for managing shared dependencies while maintaining isolation. A workspace-first approach lets you treat local packages as first-class citizens – no symlink hacks, no path gymnastics.
A critical failure occurred early: the root pyproject.toml contained a ghost dependency, langchain-qa, which didn’t exist in the file system. It is a reminder that coding assistants still need constant checking. This halted the uv sync process immediately. Rather than commenting it out or working around it, we performed a removal from both the workspace members list and the dependency declarations.
The takeaway for backend engineers is clear: workspace integrity is binary. If your lockfile or project manifest references a non-existent member, the entire dependency resolution graph collapses. We favored an explicit uv add within the package subdirectory to ensure the meeting-summarizer stayed portable yet properly integrated into the monorepo.
Composable Logic with LangChain Expression Language (LCEL)
The core implementation moved away from the now-deprecated LLMChain in favor of LangChain Expression Language (LCEL). The decision was based on two needs: transparency and streaming support for production-ready LLM pipeline.
Legacy chains often felt like black boxes – data went in, output came out, and what happened in between was opaque. LCEL, using the pipe operator (|), defines a linear transformation of data that you can inspect, extend, and test at each step.
self.workflow = (
{"summary": self.summarize_chain}
| RunnablePassthrough.assign(action_items=self.action_chain)
| RunnablePassthrough.assign(priorities=self.priority_chain)
)We chose RunnablePassthrough.assign over simple sequential execution to maintain state throughout the chain. In a standard sequential chain, output A becomes input B and A is discarded, which is common in production-ready LLM pipelines. By using assign, we effectively build a dictionary that accumulates the summary, then appends action_items, and finally priorities. This pattern is essential for backend services where the final response must return all intermediate computation steps to the client – not just the final leaf node’s output.
Inference Optimization: The Groq Advantage
When selecting an inference engine, we prioritized latency over model size. While OpenAI’s GPT-4o is a sensible default, we opted for Groq’s Llama-3-70b implementation, driven by the LPU (Language Processing Unit) architecture, which delivers tokens at speeds exceeding 250 tokens per second.
For a backend summarization service, two metrics dominate: Time to First Token (TTFT) and total generation time. Using the langchain-groq wrapper, we instantiated ChatGroq with temperature=0. In production, non-deterministic outputs are the enemy of reliable parsing. By pinning temperature to zero, the extracted “Action Items” remain consistent across identical inputs – critical when downstream systems depend on structured output.
The known failure mode here is rate-limiting, which is a real concern at scale. For this prototype, the trade-off for raw throughput speed was justified. As usage grows, implementing a retry strategy with exponential backoff or a fallback inference provider is the natural next step.
Observability: Lighting Up the Black Box
Building production-ready LLM pipelines without tracing is like debugging a distributed system without logs. We integrated LangSmith by setting a single environment variable (while providing a LangSmith API key as well):
LANGCHAIN_TRACING_V2=trueNo business logic was touched. This follows the Twelve-Factor App methodology, where configuration is strictly separated from code. The tracing layer attaches at the framework level, not the application level.
The integration immediately revealed the hidden latency of each sub-chain. The “Priority Classification” step depends on the output of “Action Item Extraction,” creating a sequential bottleneck. Through LangSmith, we confirmed that the bottleneck wasn’t the LLM’s reasoning quality – it was the sequential nature of the calls themselves. If scaling becomes necessary, the next architectural decision would be to parallelize independent tasks using RunnableParallel.
Crucially, tracing from day one give you a concrete baseline: the current 3-step sequence completes in approximately 2.5 seconds – well within the acceptable range for an asynchronous meeting processor. That number is only meaningful because we measured it.
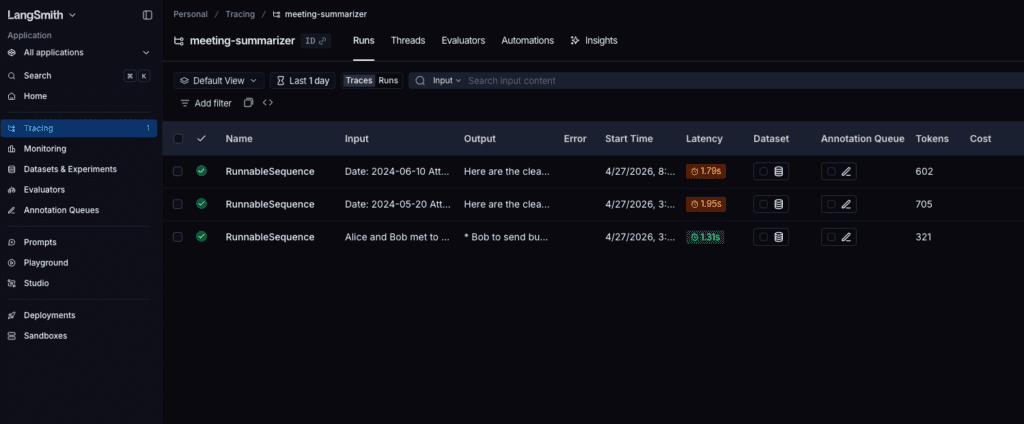
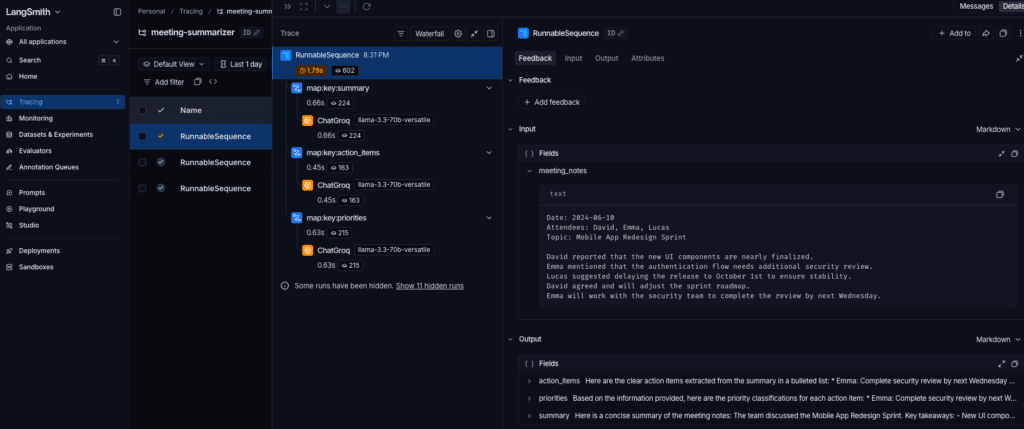
Testing the Unpredictable: Mocks vs. Reality
The testing strategy for this package uses a deliberate two-tier approach.
Tier 1 – Unit Tests with Mocks: We used unittest.mock to simulate the LLM’s invoke method. This is critical for CI/CD production-ready LLM pipelines where burning API credits or relying on external network stability is unacceptable.
with patch("meeting_summarizer.main.ChatGroq") as mock_groq:
summarizer = MeetingSummarizer()
summarizer.workflow = MagicMock()
summarizer.workflow.invoke.return_value = {"summary": "Mock summary", ...}Tier 2 – Integration Tests with Graceful Skipping: We gated live API tests behind a pytest.mark.skipif environment variable check. A load_dotenv() call at the top of the test suite ensures that if a .env file exists, credentials are loaded automatically. If not, the test skips cleanly rather than failing with a missing credentials error.
This “fail-fast or skip” logic is a small but important cultural choice: developers should never see red bars caused by configuration issues rather than code bugs. Noisy test suites erode trust in the testing process itself.
Conclusion: The Backend Engineer’s Production-Ready LLM pipeline
Building LLM-powered tools is no longer about prompt engineering in a vacuum – it’s about robust systems engineering. The patterns applied here map cleanly to any LLM backend project:
- Use uv workspaces for dependency management in monorepos. Treat workspace integrity as non-negotiable.
- Use LCEL over legacy chains for composable, transparent, streaming-compatible production-ready LLM pipelines.
- Choose your inference provider based on measurable metrics – TTFT and throughput – not brand recognition.
- Integrate observability (LangSmith or equivalent) from day one, not as an afterthought. A 2.5-second baseline means nothing if you only measured it after a performance complaint.
- Write two-tier tests: fast mocked unit tests for CI, gracefully skipped integration tests for live validation.
Choosing Llama 3 on Groq allowed near-instantaneous summarization, while the MeetingSummarizer class abstraction keeps LLM implementation details hidden from the rest of the application. For the backend engineer, the LLM is just another RPC call – one that requires rigorous tracing, deterministic configuration, and a solid testing harness to be truly a production-ready LLM pipeline.
For reference, here is the full Python script that performs the summarization:
import os
import logging
from typing import Dict, List, Any
from dotenv import load_dotenv
from langchain_groq import ChatGroq
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# Configure logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
logger = logging.getLogger("meeting-summarizer")
# Load environment variables
load_dotenv()
def get_llm():
"""Initialize the Groq LLM."""
api_key = os.getenv("GROQ_API_KEY")
if not api_key or api_key == "your_groq_api_key_here":
logger.warning("GROQ_API_KEY is not set correctly. LLM calls will fail.")
return ChatGroq(
model="llama-3.3-70b-versatile",
temperature=0,
groq_api_key=api_key
)
def create_summarizer_chain(llm):
"""Create a chain for summarizing meeting notes."""
prompt = ChatPromptTemplate.from_messages([
("system", "You are a professional secretary. Summarize the following meeting notes concisely."),
("user", "{meeting_notes}")
])
return prompt | llm | StrOutputParser()
def create_action_item_chain(llm):
"""Create a chain for extracting action items."""
prompt = ChatPromptTemplate.from_messages([
("system", "Extract a list of clear action items from the following summary. Format as a bulleted list."),
("user", "{summary}")
])
return prompt | llm | StrOutputParser()
def create_priority_chain(llm):
"""Create a chain for classifying priority of action items."""
prompt = ChatPromptTemplate.from_messages([
("system", "Classify the priority (High, Medium, Low) for each of the following action items. Explain why."),
("user", "{action_items}")
])
return prompt | llm | StrOutputParser()
class MeetingSummarizer:
def __init__(self):
self.llm = get_llm()
self.summarize_chain = create_summarizer_chain(self.llm)
self.action_chain = create_action_item_chain(self.llm)
self.priority_chain = create_priority_chain(self.llm)
# Multi-step workflow using LCEL
self.workflow = (
{"summary": self.summarize_chain}
| RunnablePassthrough.assign(action_items=self.action_chain)
| RunnablePassthrough.assign(priorities=self.priority_chain)
)
def process(self, meeting_notes: str) -> Dict[str, Any]:
"""Run the full workflow on meeting notes."""
logger.info("Starting meeting notes processing...")
try:
result = self.workflow.invoke({"meeting_notes": meeting_notes})
logger.info("Processing completed successfully.")
return result
except Exception as e:
logger.error(f"Error during processing: {e}")
return {"error": str(e)}
if __name__ == "__main__":
# Simple verification script
# sample_notes = """
# Date: 2024-05-20
# Attendees: Alice, Bob, Charlie
# Topic: Q3 Project Orion Launch
# Alice reported that the frontend is 80% complete.
# Bob mentioned that the backend API needs more load testing.
# Charlie suggested we move the launch date to September 15th to allow for more QA.
# Alice agreed and will update the project timeline.
# Bob will coordinate with the DevOps team for load testing by next Friday.
# """
sample_notes = """
Date: 2024-06-10
Attendees: David, Emma, Lucas
Topic: Mobile App Redesign Sprint
David reported that the new UI components are nearly finalized.
Emma mentioned that the authentication flow needs additional security review.
Lucas suggested delaying the release to October 1st to ensure stability.
David agreed and will adjust the sprint roadmap.
Emma will work with the security team to complete the review by next Wednesday.
"""
summarizer = MeetingSummarizer()
output = summarizer.process(sample_notes)
if "error" in output:
print(f"FAILED: {output['error']}")
else:
print("\n--- SUMMARY ---")
print(output.get("summary"))
print("\n--- ACTION ITEMS ---")
print(output.get("action_items"))
print("\n--- PRIORITIES ---")
print(output.get("priorities"))