Resilience engineering is crucial for LLM reliability in production environments. This involves handling various types of failures, such as rate limits, timeouts, and model-specific errors, to ensure a seamless user experience.
When it comes to Large Language Models, reliability is not just a nice-to-have, but a must-have. The last thing you want is for your users to experience frustrating downtime or errors, which can lead to a loss of trust and ultimately, a loss of customers. That’s why resilience engineering is essential for ensuring LLM reliability in production environments.
But what exactly does resilience engineering entail? In short, it’s the practice of designing and implementing systems that can withstand and recover from failures. This involves identifying potential failure points, developing strategies to mitigate them, and putting in place robust monitoring and logging systems to detect issues before they become major problems.
One key aspect of resilience engineering is understanding LLM reliability patterns. By studying how LLMs behave under different conditions, developers can identify common failure modes and develop targeted solutions to prevent them. This might involve implementing rate limiting to prevent overloading, designing retry mechanisms to handle temporary timeouts, or developing custom error handling to catch model-specific errors.
By embracing resilience engineering and understanding LLM reliability patterns, developers can build LLMs that are more resilient, more reliable, and ultimately, more trustworthy. This not only improves the user experience but also helps to reduce the risk of downtime and errors, which can have significant financial and reputational implications. By taking a proactive approach to resilience engineering, developers can ensure that their LLMs are always available, always accurate, and always delivering the best possible experience for their users.

Resilience Engineering Strategies
Handle Cascades, Timeouts, Provider Hiccups, and Partial Outages with Ease
When working with LLMs, it’s inevitable that we’ll encounter issues that can bring our entire system down. Whether it’s a timeout, a provider hiccup, or a partial outage, we need to be prepared to handle these cascades gracefully. After all, a resilient system is one that can recover from unexpected setbacks with ease.
Implement Retry Logic with Exponential Backoff and Jitter
One of the most effective ways to handle LLM failures is to implement retry logic with exponential backoff and jitter. This strategy allows us to retry failed requests with increasing delays between attempts, while also introducing a random element (jitter) to avoid the dreaded retry storms. By spacing out our retries, we can prevent a single failure from becoming a catastrophic event.
With these resilience engineering strategies in place, we can build systems that can handle even the most unexpected LLM failures with ease. By combining retry logic, circuit breakers, and a healthy dose of anticipation, we can ensure that our systems are always ready to adapt to the ever-changing landscape of LLM reliability patterns.

Circuit Breaker Implementation
In the realm of large language models, a well-designed circuit breaker can make all the difference in maintaining the reliability and responsiveness of your application. By implementing circuit breakers, you can prevent cascading failures and ensure a smoother experience for your users.
To achieve this, circuit breakers should be per-provider and per-model, allowing for separate breaker states for each endpoint. This approach enables you to isolate issues specific to individual LLM providers or models, preventing a single failure from bringing down your entire system.
One crucial aspect of circuit breaker design is the use of Retry-After headers. By incorporating these headers into your implementation, you can avoid retry storms and minimize the risk of cascading traffic. This is particularly important in scenarios where multiple requests are being made to the same endpoint, and a failure occurs.
So, how can you implement circuit breakers effectively? The answer lies in wrapping your LLM providers with circuit breaker logic. This approach allows you to decouple your application’s logic from the underlying LLM provider, making it easier to switch between different providers or models as needed.
To maximize LLM reliability patterns, it’s essential to follow a few key best practices. Firstly, ensure that your circuit breaker is designed to detect and respond to changes in the LLM provider’s availability in real-time. This can be achieved through the use of health checks and monitoring tools. Secondly, configure your circuit breaker to adapt to changing traffic patterns and LLM provider performance. By doing so, you can prevent overloading your system with unnecessary requests and ensure that your application remains scalable and responsive.

Timeout Handling and Fallback Strategies
When it comes to large language models, the importance of timeout handling and fallback strategies cannot be overstated. These techniques enable you to create robust systems that can handle unexpected failures and maintain high availability.
Context-Aware Timeout Values
Different LLM operations require varying amounts of time to complete. For instance, classification tasks can be completed within a few milliseconds, while long generations may take several minutes. To optimize performance, it’s essential to set context-aware timeout values for each operation. This approach ensures that tasks are executed efficiently without blocking other tasks or inflating costs.
Fail-Fast Policies
Implementing fail-fast policies is crucial for preventing cascading failures. These policies enable your system to quickly identify and respond to failures without blocking threads or inflating costs. By doing so, you can maintain system availability and prevent disruptions to your users.
Timeouts for Long-Running Operations
Long-running operations, such as long generations, can block other tasks and impact system performance. By using timeouts, you can prevent these operations from monopolizing resources and ensure that other tasks can execute efficiently.
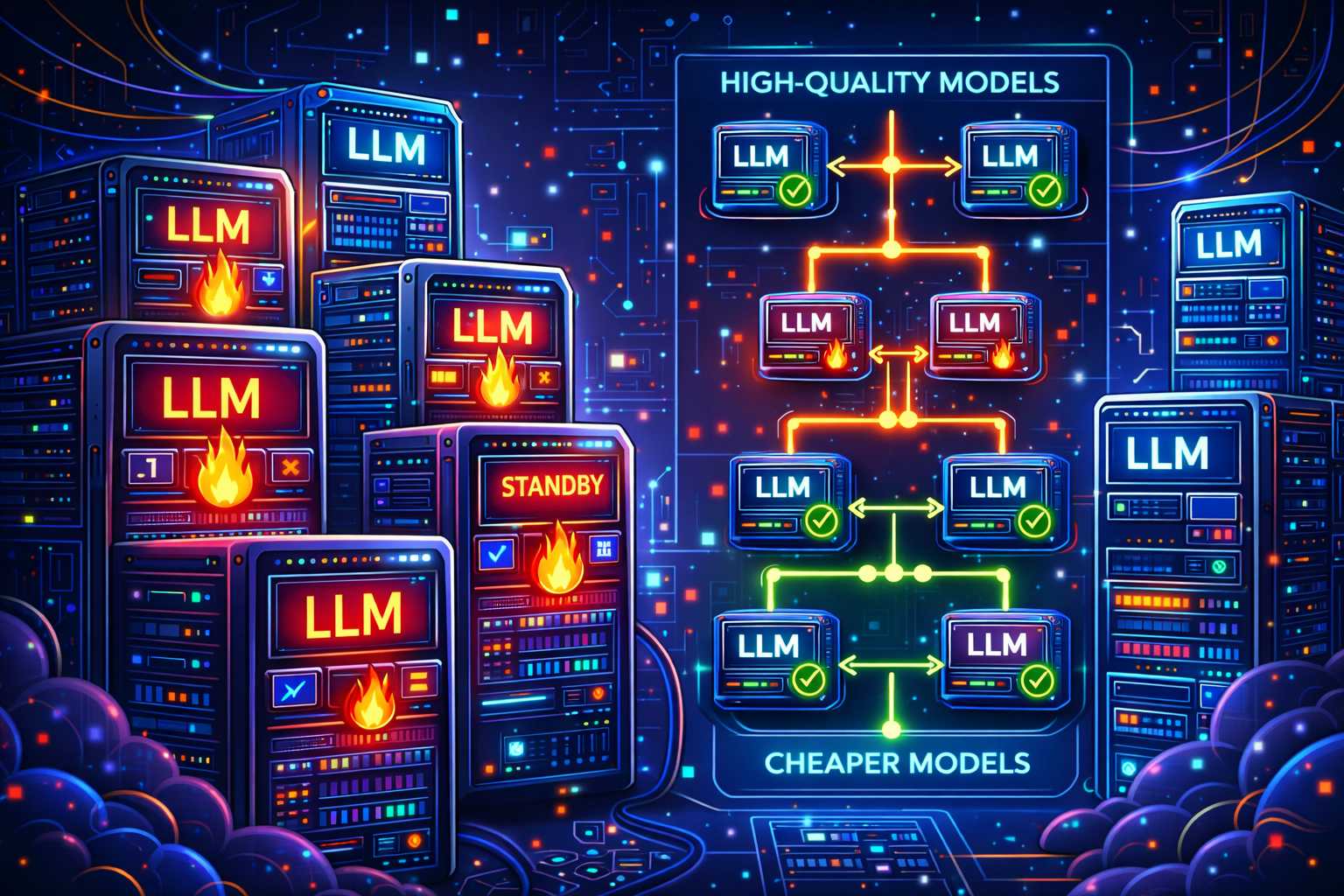
Fallback Models for Continuity
When primary LLMs fail, fallback models come into play. These models provide continuity and enable your system to maintain high availability. By implementing fallback chains that cascade from high-quality/expensive models to cheaper or simpler alternatives, you can ensure that your system remains operational even in the event of a failure.
LLM Reliability Patterns
By incorporating timeout handling and fallback strategies, you can establish effective LLM reliability patterns. These patterns enable you to create robust systems that can handle unexpected failures and maintain high availability. By prioritizing LLM reliability, you can ensure that your system remains operational and continues to deliver high-quality results to your users.
Idempotence and Observability
Idempotence is the unsung hero of resilient systems. It’s the key to preventing retries from executing side-effects twice, ensuring that your application remains stable and efficient. Think of it like a “do-no-harm” principle – a retry should only happen once, without causing extra work or impacting performance.
To achieve this, implement deduplication, which limits the total retry work across nested calls. This ensures that each retry is only executed once, avoiding duplicate work and minimizing the risk of cascading failures. It’s like having a “retry shield” that protects your system from excessive retries.
But idempotence is just the beginning. To prevent excessive retries, implement retry budgets, which set a limit on the number of retries allowed within a given timeframe. This ensures that your application doesn’t get stuck in an infinite loop of retries, wasting resources and impacting user experience.
Logging is also crucial in this context. By logging retries, fallback triggers, circuit open/close events, and error classes, you can tune thresholds and fine-tune your resilience patterns. It’s like having a “retry dashboard” that provides real-time visibility into your application’s behavior.
Monitoring LLM performance is also vital, as it allows you to adjust resilience patterns as needed. By tracking key metrics, you can identify areas for improvement and optimize your application’s reliability. And when issues arise, provide observability tools for developers to troubleshoot and resolve problems quickly – it’s like having a “system health” report at their fingertips.
By implementing idempotence, deduplication, retry budgets, and logging, you can ensure that your application remains stable, efficient, and reliable. And by monitoring LLM reliability patterns, you can fine-tune your resilience patterns and deliver a seamless user experience.

Conclusion
We have discussed different approaches to building resilient Large Language Model systems. It is necessary to follow best practices in order to build quality systems. LLM reliability in production requires resilience engineering, not just successful responses – you must handle cascades, timeouts, provider hiccups, and partial outages gracefully.
Unlike typical REST APIs, LLM failures often manifest as rate limits (429), timeouts, or model-specific errors (e.g., context length exceeded or content filter refusals), requiring dedicated patterns beyond standard retry logic. To achieve LLM reliability patterns, circuit breakers detect sustained LLM provider failures and “open” to prevent continual retries, stopping wasted latency and token spend while giving the provider time to recover.
Efficient retry strategies use exponential backoff with jitter, capped retries, and respect Retry-After headers to avoid retry storms and cascading traffic. However, this is not just about implementing a generic retry logic, but rather about crafting LLM reliability patterns that are tailored to the specific needs of your system. For instance, timeout handling needs context-aware values – short timeouts for classification, longer for long generations – to fail fast without blocking threads or inflating costs.
Fallback models provide continuity when primary LLMs fail, often cascading from high-quality/expensive models to cheaper or simpler alternatives on repeated failures. Idempotency, deduplication, and retry budgets prevent retries from executing side-effects twice and limit total retry work across nested calls. By building these patterns before production, you can establish a robust foundation for your LLM system and ensure that it can handle the inevitable outages and failures that occur in production.
