By 2028, 60% of software engineering teams will use AI evaluation and observability platforms – up from just 18% in 2025.
The future of software engineering is rapidly evolving, and AI-powered tools are at the forefront of this revolution. One of the most significant trends emerging in this space is the adoption of LLM systems, which are poised to become a baseline skill for backend engineers. These Large Language Model systems are changing the way we approach software development, enabling faster, more efficient, and more accurate coding practices.
But what does this mean for traditional monitoring methods? In the past, monitoring your system’s performance was a straightforward task – it was simply a matter of checking whether it was running. However, with the rise of AI-powered systems, this approach is no longer sufficient. That’s where LLM observability comes in – a game-changing concept that tells you not just whether your system is up and running, but whether it’s behaving correctly.
In other words, LLM observability is about more than just system uptime – it’s about ensuring that your AI-powered systems are producing the right output. And that’s particularly important when it comes to non-deterministic AI outputs. These types of outputs are inherently unpredictable, and without LLM observability, it’s impossible to know whether the results are accurate or not.
As we move forward into the next decade, it’s clear that LLM observability will play a critical role in the success of software engineering teams. By 2028, a staggering 60% of teams will be using AI evaluation and observability platforms – a dramatic increase from the 18% we saw in 2025. This shift towards LLM observability is an opportunity for teams to gain a competitive edge, ensure the accuracy of their AI-powered systems, and deliver better outcomes for their users.

Undestanding Outputs is Crucial
More than 50% of organizations using AI experienced at least one negative consequence from AI inaccuracy. It’s a sobering statistic that highlights the importance of robust AI systems with predictable outcomes. Inaccurate AI can lead to costly mistakes, damaged reputations, and lost business.
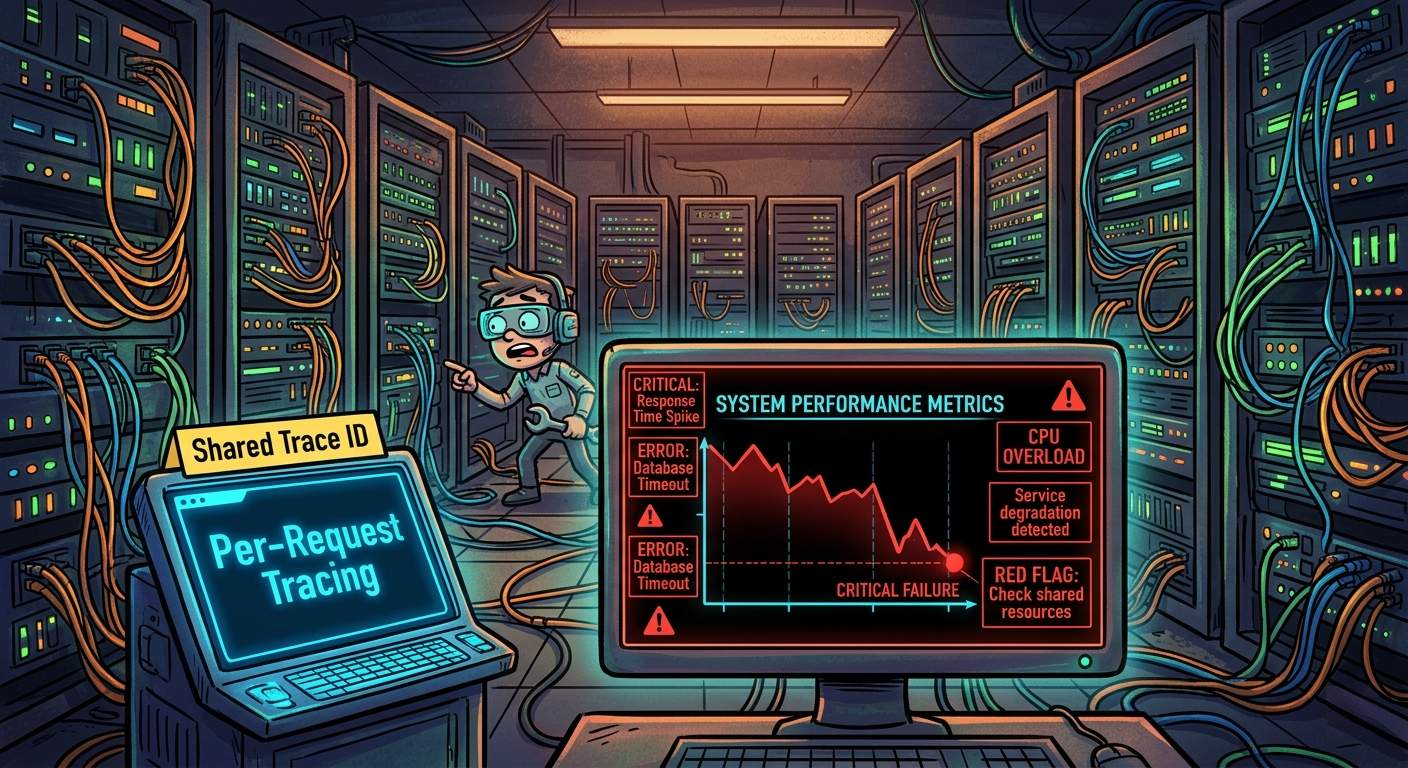
Fortunately, modern AI solutions offer a way to mitigate these risks. By incorporating robust per-request tracing, organizations can catch and localize failures due to AI inaccuracy before they become major issues. This proactive approach not only helps prevent errors but also streamlines the process of identifying and resolving problems.
In the context of production Language Model requests, logging is essential for effective LLM observability. This process involves tracking four core signals: traces, metrics, and events. Traces provide a chronological record of events, metrics offer insight into system performance, and events capture specific occurrences within the system.
A shared trace ID is the key to linking all logged signals. This ID serves as a unique identifier for each request, allowing organizations to track its journey through the system. With this information, developers can pinpoint areas of weakness and optimize their systems for better performance and accuracy.
By prioritizing LLM observability through logging and tracing, organizations can reduce the risk of AI inaccuracies and improve overall system reliability. By monitoring their systems in real-time, they can identify potential issues before they become major problems, ensuring that their AI solutions deliver the expected results and maintain a high level of trust with their customers.
Budget Is Always Important
Cost attribution is non-trivial and requires breaking down token usage per request.
In the world of Large Language Models, understanding the cost of each request can be a daunting task. It’s not as simple as just tracking the number of tokens used – we need to dive deeper into the specifics of each request to truly attribute the cost.
One way to tackle this challenge is by aggregating token usage by user, feature, or model. This allows us to surface budget allocation in a clear and actionable way. By doing so, we can identify areas where costs are high and opportunities for optimization. For instance, if we notice that a particular feature or user is consistently using a large number of tokens, we can revisit the implementation to see if there are any ways to reduce the token usage.
But cost attribution is just the tip of the iceberg. Another crucial aspect of LLM development is logging and observability. It’s essential to log traces without evaluating them, as this is what truly enables real observability. Evaluating logs on the fly can be expensive, and it’s not a substitute for proper logging and monitoring. By logging traces without evaluation, we can gain valuable insights into how our LLM is performing and identify areas for improvement.
However, there’s one important metric that’s often overlooked: output quality scoring. Engineers tend to focus on metrics like latency, throughput, and accuracy, but output quality is just as critical. It’s what sets a great LLM apart from a good one. By incorporating output quality scoring into our development process, we can ensure that our LLM is producing high-quality responses that meet the needs of our users.
The LLM Observability Tooling Space Has Split into Three Camps
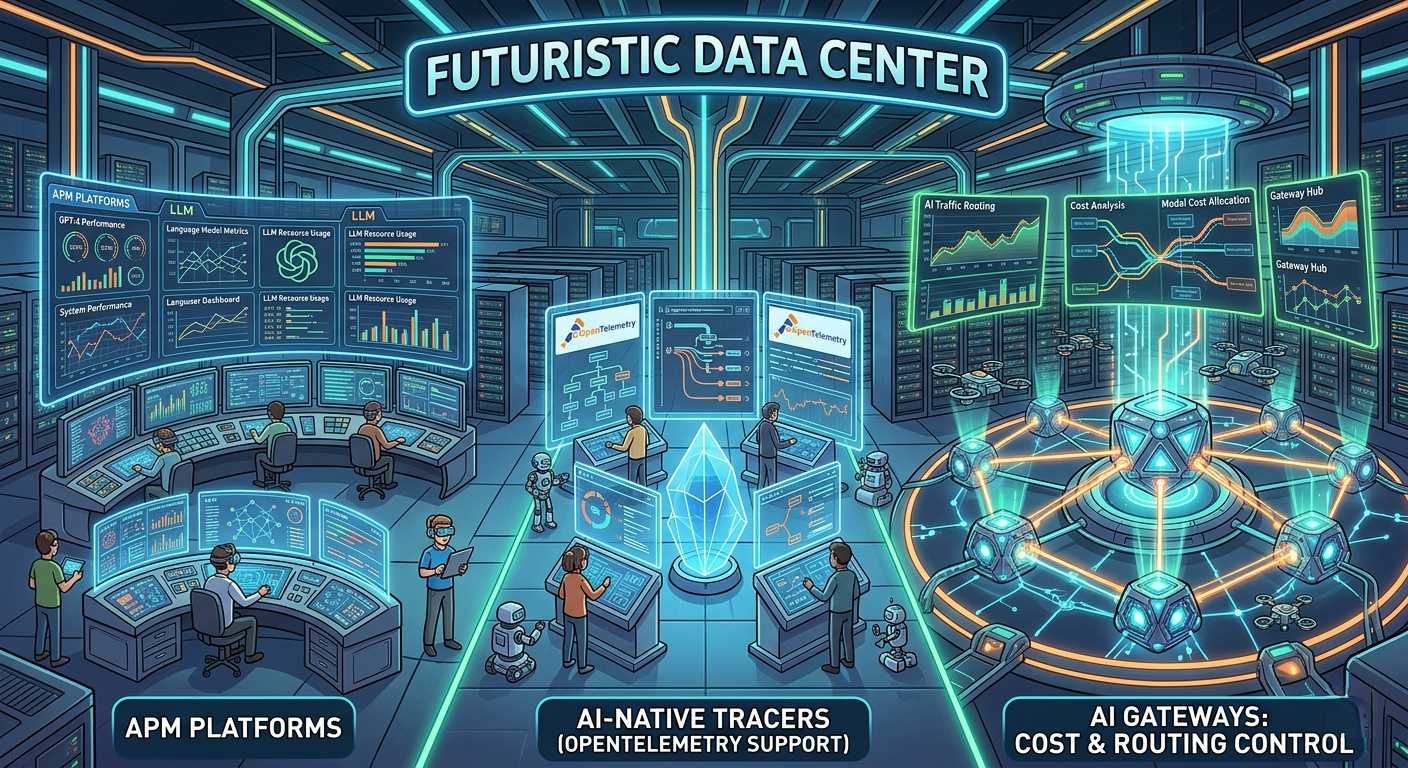
The world of Large Language Models has reached a critical juncture, with a clear divide emerging in the LLM observability tooling space. Gone are the days of a single, all-encompassing solution; instead, three distinct camps have formed, each with its own strengths and weaknesses.
Traditional APM platforms have added LLM tabs to their offerings, allowing users to gain insights into their AI systems. Datadog and New Relic are two notable examples, leveraging their existing infrastructure monitoring capabilities to provide a more comprehensive view of LLM performance. However, these additions are often tacked on, rather than being designed from the ground up to support the unique requirements of LLMs.
AI-native tracers, on the other hand, have taken a more holistic approach. Langfuse is a prime example, offering strong OpenTelemetry support that enables end-to-end tracing of LLM workflows. This approach provides a more unified view of the entire system, from model input to output, and is better equipped to handle the complex, distributed nature of modern LLM architectures.
Finally, AI gateways like Helicone and Portkey have taken a more control-oriented approach, incorporating built-in cost and routing control into their offerings. This allows users to fine-tune their LLM workflows, optimizing performance and reducing costs in the process. With RAG pipelines requiring end-to-end tracing that covers retrieval quality, these gateways are well-positioned to meet the needs of the LLM community.
Ultimately, infrastructure-only monitoring is insufficient for LLMs. To truly unlock their potential, we need to adopt a more comprehensive approach to LLM observability, one that covers model output and retrieval quality, as well as query latency, retrieval precision, and vector store behavior. Only then can we ensure that our AI systems are running at peak performance, delivering the best possible results to users.
Different Tools For Production
Langfuse is an ideal option for teams with data residency constraints. It’s no secret that data residency regulations can be a challenge for businesses operating globally. That’s where Langfuse comes in – an open-source solution that allows you to host your data within your own infrastructure, ensuring compliance with even the strictest data residency laws.
Not only does Langfuse cater to your compliance needs, but it’s also designed to be highly customizable and manageable. It’s open-source and self-hostable, making it a cost-effective solution for businesses of all sizes. Plus, its self-hostable nature means that you have complete control over your data, which is especially important for teams with sensitive information.
But what really sets Langfuse apart is its strong support for OpenTelemetry. This means that you can collect and analyze data from your LangChain models with ease, gaining valuable insights into their performance and behavior. And with LangChain being tightly coupled with Langfuse, you can rest assured that your models will be running smoothly and efficiently.
However, running LLMs in production without observability is operationally reckless. We’ve all heard horror stories about cost spikes, silent quality regressions, and compliance audit failures that can bring even the most successful businesses to their knees. The truth is, these problems are all preventable with proper observability.
LLM observability is the key to unlocking a stress-free and successful LLM deployment. Not only does it prevent problems that nothing else will catch, but it also provides you with the data and insights you need to make informed decisions about your models. And in 2026, running LLMs without observability will be unacceptable. So why wait? Make the switch to Langfuse today and experience the benefits of LLM observability for yourself.

Remove the Curtain From LLM Output
LLM observability is no longer a nice-to-have feature you tack on after launch. It’s a must-have from day one. Instrumenting your system costs an hour upfront, but it saves weeks of debugging production incidents that would otherwise leave you scratching your head. Think about it: every minute, every request, and every interaction is a potential point of failure. By instrumenting early, you gain the insights you need to avoid those failures in the first place.
The tooling landscape is mature enough in 2026 that there’s no excuse to build a custom logging solution from scratch. Choose a battle-tested solution that fits your needs: Langfuse for open-source control, LangSmith if you’re already agent-heavy, or an Application Performance Monitoring (APM) layer if you’re already invested in Datadog. The key is to find a solution that’s easy to integrate and provides the visibility you need.
When it comes to LLM observability, start with the four core signals: latency, cost, quality, and failures. Focus on getting those metrics flowing per-request first. Then, once you have real data to react to, layer in evals and dashboards to help you make sense of it all. This is where the real magic happens: turning data into actionable insights that drive business outcomes.
As AI becomes a load-bearing infrastructure in production systems, the engineers who own observability will own reliability. And in 2026, reliability is the moat. By prioritizing LLM observability, you’re not just building a better system – you’re building a business that can adapt, innovate, and thrive in a rapidly changing landscape.